- 基础集群
- MySQL主从同步原理
- 搭建主从集群
- 配置master主服务
- 配置slave从服务
- 部分同步
- GTID同步集群
- 集群扩容与MySQL数据迁移
- 复杂集群
- 半同步复制
- 主从集群与读写分离
- 更复杂的集群结构
- 高可用集群
- MMM
- MHA
- MGR
- 分库分表
- 分库分表的方式
- 分库分表要解决哪些问题
- 什么时候需要分库分表
基础集群
- MySQL主从同步原理(MySQL的Binlog默认是不打开的)
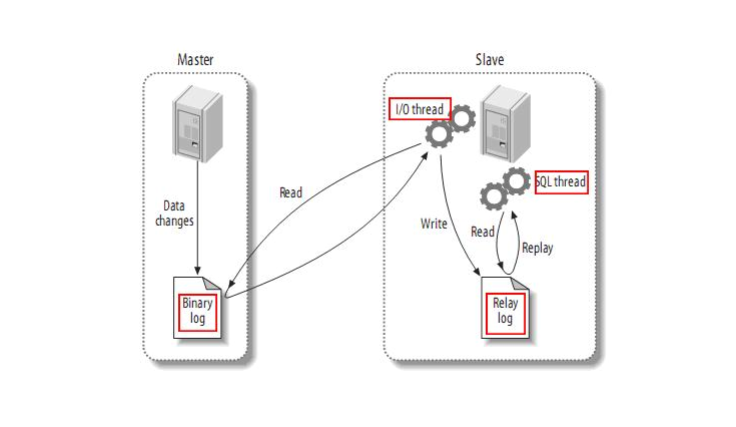
- 在主库上打开Binlog日志,记录对数据的每一步操作
- 然后在从库上打开RelayLog日志,用来记录跟主库一样的Binlog日志
- 将RelayLog中的操作日志在自己数据库中进行异步的重演
- 搭建集群的两个必要条件
- MySQL版本必须一致
- 集群中各个服务器的时间需要同步
- 搭建主从集群
- 配置master主服务:
/etc/my.cnf- 打开binlog日志:
log_bin log_bin-index - 指定severId:
server-id - 重启服务:
service mysqld restart - 给root用户分配一个replication slave的权限
GRANT REPLICATION SLAVE ON *.* TO 'root'@'%';flush privileges;show master status;查看主节点同步状态- 这个指令结果中的File和Position记录的是当前日志的binlog文件以及文件中的索引
- 后面的Binlog_Do_DB和Binlog_Ignore_DB这两个字段是表示需要记录binlog文件的库以及不需要记录binlog文件的库
- 没有进行配置,就表示是针对全库记录日志
- 开启binlog后,数据库中所有操作都会被记录到datadir中,以一组轮询文件的方式循环记录
- 指令查到的File和Position就是当前日志的文件和位置
- 后面配置从服务时,就需要通过这个File和Position通知从服务从哪个地方开始记录binLog
- 在实际生产环境中,通常不会直接使用root用户,而会创建一个拥有全部权限的用户来负责主从同步
- 打开binlog日志:
- 配置slave从服务:
/etc/my.cnfserver-id relay-log relay-log-index log-bin- 启动mysqls的服务,并设置他的主节点同步状态
- 设置同步主节点
CHANGE MASTER TOMASTER_HOST='192.168.232.128',MASTER_PORT=3306,MASTER_USER='root',MASTER_PASSWORD='root',MASTER_LOG_FILE='master-bin.000004',MASTER_LOG_POS=156,GET_MASTER_PUBLIC_KEY=1;
- MASTER_LOG_FILE和MASTER_LOG_POS必须与主服务中查到的保持一致
- 后续如果要检查主从架构是否成功,也可以通过检查主服务与从服务之间的File和Position这两个属性是否一致来确定
start slave;开启slaveshow slave status \G;查看主从同步状态- 查看MASTER_LOG_FILE和READ_MASTER_LOG_POS与主节点保持一致,就表示这个主从同步搭建是成功的
- Replicate_开头的属性,指定了两个服务之间要同步哪些数据库、哪些表的配置
- 设置同步主节点
Slave_SQL_Running=no如果在slave从服务上查看slave状态,发现这个属性,就表示主从同步失败了- 有可能是因为在从数据库上进行了写操作,与同步过来的SQL操作冲突了
- 也有可能是slave从服务重启后有事务回滚了
- 重启主从同步
stop slave;set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;start slave;
- 另一种解决方式就是重新记录主节点的binlog文件消息(不太常用)
stop slave;change master to .....start slave;- 这种方式要注意binlog的文件和位置,如果修改后和之前的同步接不上,那就会丢失部分数据。所以不太常用
- 重启主从同步
- 配置master主服务:
- 部分同步
- Master端:
/etc/my.cnfbinlog-do-db需要同步的数据库名binlog-ignore-db不备份的数据库
- Slave端:
/etc/my.cnfreplicate-do-dbsalve库名称与master库名相同replicate-rewrite-db = masterdemo -> masterdemo01主从库名映射
replicate-wild-do-table指定需要同步的表
- Master端:
- GTID同步集群:也是基于Binlog来实现主从同步,只是他会基于一个全局的事务ID来标识同步进度
- GTID即全局事务ID,全局唯一并且趋势递增,他可以保证为每一个在主节点上提交的事务在复制集群中可以生成一个唯一的ID
- 流程
- 首先从服务器会告诉主服务器已经在从服务器执行完了哪些事务的GTID值
- 然后主库会有把所有没有在从库上执行的事务,发送到从库上进行执行
- 并且使用GTID的复制可以保证同一个事务只在指定的从库上执行一次
- 这样可以避免由于偏移量的问题造成数据不一致
- Master端:
/etc/my.cnfgtid_mode=onenforce_gtid_consistency=onlog_bin=onserver_id=单独设置一个binlog_format=row
- Slave端:
/etc/my.cnfgtid_mode=onenforce_gtid_consistency=onlog_slave_updates=1server_id
- 然后分别重启主服务和从服务,就可以开启GTID同步复制方式
- 集群扩容与MySQL数据迁移
- 扩展到一主多从的集群架构只需要增加一个binlog复制就行了
- 运行过程中扩展新的从节点(数据全量复制):mysqldump 数据备份恢复操作
mysqldump -u root -p --all-databases > backup.sql导出mysql -u root -p < backup.sql导入- 然后配置Slave从服务的数据同步
复杂集群
- 异步复制:MySQL主从集群默认采用的是一种异步复制的机制。主服务在执行用户提交的事务后,写入binlog日志,然后就给客户端返回一个成功的响应了。而binlog会由一个dump线程异步发送给Slave从服务
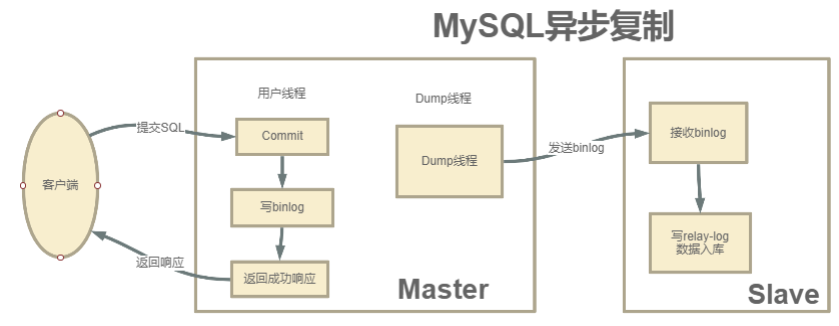
- 由于这个发送binlog的过程是异步的。主服务在向客户端反馈执行结果时,是不知道binlog是否同步成功了的
- 这时候如果主服务宕机了,而从服务还没有备份到新执行的binlog,那就有可能会丢数据
- 半同步复制:介于异步复制和全同步复制之前的机制
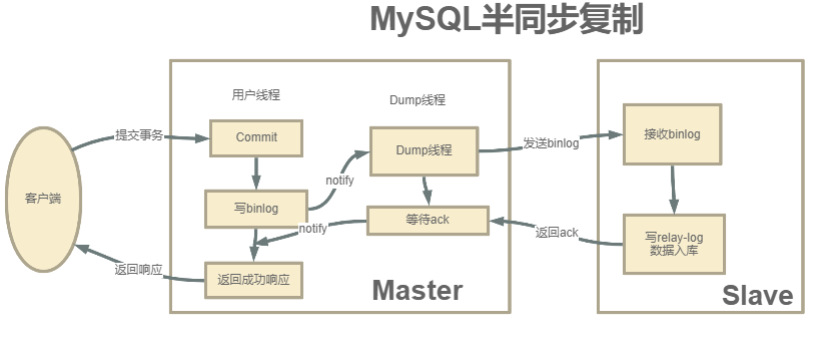
- 主库在执行完客户端提交的事务后,并不是立即返回客户端响应,而是等待至少一个从库接收并写到relay log中,才会返回给客户端
- MySQL在等待确认时,默认会等10秒,如果超过10秒没有收到ack,就会降级成为异步复制
- 这种半同步复制相比异步复制,能够有效的提高数据的安全性
- 但是这种安全性也不是绝对的,他只保证事务提交后的binlog至少传输到了一个从库,并且并不保证从库应用这个事务的binlog是成功的
- 半同步复制机制也会造成一定程度的延迟,这个延迟时间最少是一个TCP/IP请求往返的时间
- 当从服务出现问题时,主服务需要等待的时间就会更长,要等到从服务的服务恢复或者请求超时才能给用户响应
- 搭建半同步复制集群:基于特定的扩展模块(semisync_master.so semisync_slave.so)
- 在主服务上安装 semisync_master 模块
install plugin rpl_semi_sync_master soname 'semisync_master.so';set global rpl_semi_sync_master_enabled=ON;打开半同步复制show global variables like 'rpl_semi%';- rpl_semi_sync_master_timeout就是半同步复制时等待应答的最长等待时间,默认是10秒
- 半同步复制有两种方式,默认AFTER_SYNC方式
- AFTER_SYNC:主库把日志写入binlog,并且复制给从库,然后开始等待从库的响应。从库返回成功后,主库再提交事务,接着给客户端返回一个成功响应
- AFTER_COMMIT:在主库写入binlog后,等待binlog复制到从库,主库就提交自己的本地事务,再等待从库返回给自己一个成功响应,然后主库再给客户端返回响应
rpl_semi_sync_master_wait_point
- 在从服务上安装 semisync_slave 模块
- `install plugin rpl_semi_sync_slave soname ‘semisync_slave.so’;
- `set global rpl_semi_sync_slave_enabled = on;``
show global variables like 'rpl_semi%';- 安装完slave端的半同步插件后,需要重启下slave服务
stop slave;start slave;
- 在主服务上安装 semisync_master 模块
- 主从集群与读写分离:MySQL主从集群是单向的,也就是只能从主服务同步到从服务,而从服务的数据表更是无法同步到主服务的
- 为了保证数据一致,通常会需要保证数据只在主服务上写,而从服务只进行数据读取(读写分离)
- MySQL主从本身是无法提供读写分离的服务的,需要由业务自己来实现
- 在MySQL主从架构中,是需要严格限制从服务的数据写入的,一旦从服务有数据写入,就会造成数据不一致
- 并且从服务在执行事务期间还很容易造成数据同步失败
- 可以在从服务中将read_only参数的值设为1(
set global read_only=1;)read_only=1设置的只读模式,不会影响slave同步复制的功能read_only=1设置的只读模式, 限定的是普通用户进行数据修改的操作,但不会限定具有super权限的用户的数据修改操作
- 限定super权限的用户写数据,可以设置
super_read_only=0- 如果要想连super权限用户的写操作也禁止,就使用
flush tables with read lock;- 这样设置也会阻止主从同步复制!
- 如果要想连super权限用户的写操作也禁止,就使用
- 为了保证数据一致,通常会需要保证数据只在主服务上写,而从服务只进行数据读取(读写分离)
- 扩展更复杂的集群结构
- 为了进一步提高整个集群的读能力,可以扩展出一主多从
- 为了减轻主节点进行数据同步的压力,可以继续扩展出多级从的主从集群
- 为了提高这个集群的写能力,可以搭建互主集群(两个服务互为主从)
- 在主服务上打开一个slave进程,并且指向slave节点的binlog当前文件地址和位置
- 可以扩展出多主多从的集群,全方位提升集群的数据读写能力
- 也可以扩展出环形的主从集群,实现MySQL多活部署
- 为了进一步提高整个集群的读能力,可以扩展出一主多从
- 主从复制延迟(读写分离后更容易体现出来),主库刚插入了数据但是从库查不到
- 面向业务的主服务数据都是多线程并发写入的,而从服务是单个线程慢慢拉取binlog
- 并行复制:
- 在从服务上设置
slave_parallel_workers为一个大于0的数 - 然后把
slave_parallel_type参数设置为LOGICAL_CLOCK
- 在从服务上设置
高可用集群
- 如果是MySQL主服务挂了,从服务是没办法自动切换成主服务的,如果要实现MySQL的高可用,需要借助一些第三方工具实现:MMM、MHA、MGR
- 对主从复制集群中的Master节点进行监控
- 自动的对Master进行迁移,通过VIP
- 重新配置集群中的其它slave对新的Master进行同步
- MMM (Master-Master replication managerfor Mysql):Mysql主主复制管理器,可以对mysql集群进行监控和故障迁移
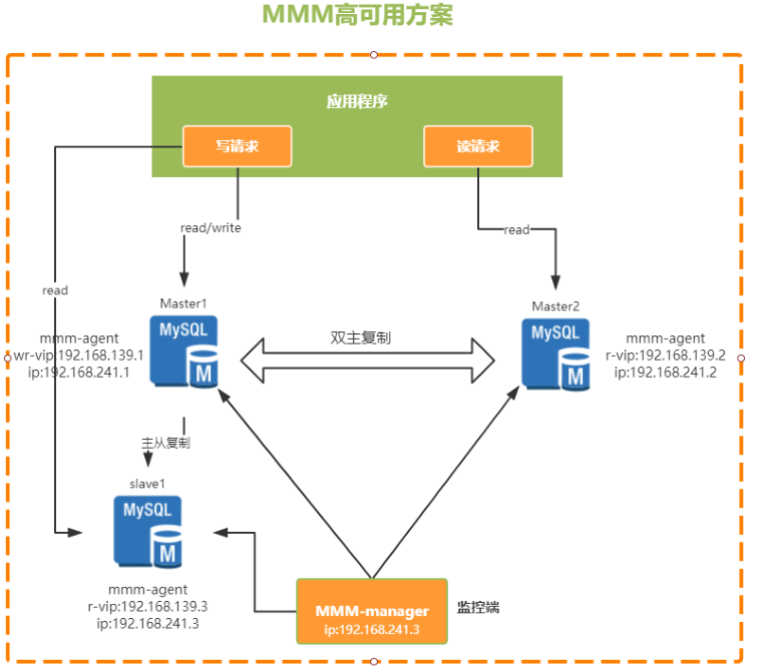
- 需要两个Master,同一时间只有一个Master对外提供服务,可以说是主备模式
- 通过一个VIP (虚拟IP) 的机制来保证集群的高可用
- 在主节点上会通过一个VIP地址来提供数据读写服务
- 当出现故障时,VIP就会从原来的主节点漂移到其他节点,由其他节点提供服务
- 优点
- 提供了读写VIP的配置,使读写请求都可以达到高可用
- 工具包相对比较完善,不需要额外的开发脚本
- 完成故障转移之后可以对MySQL集群进行高可用监控
- 缺点
- 故障简单粗暴,容易丢失事务,建议采用半同步复制方式,减少失败的概率
- 目前MMM社区已经缺少维护
- 不支持基于GTID的复制
- 适用场景
- 读写都需要高可用的
- 基于日志点的复制方式
- MHA (Master High Availability Manager and Tools for MySQL):专门用于监控主库的状态,当发现master节点故障时,会提升其中拥有新数据的slave节点成为新的master节点,在此期间,MHA会通过其他从节点获取额外的信息来避免数据一致性方面的问题
- MHA还提供了mater节点的在线切换功能,即按需切换master-slave节点
- MHA能够在30秒内实现故障切换,并能在故障切换过程中,最大程度的保证数据一致性
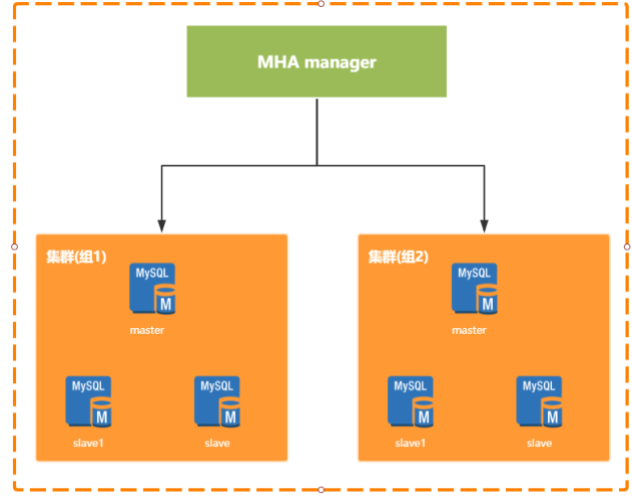
- MHA是需要单独部署的,分为Manager节点和Node节点,两种节点
- Manager节点一般是单独部署的一台机器
- Node节点一般是部署在每台MySQL机器上的
- Node节点得通过解析各个MySQL的日志来进行一些操作
- Manager节点会通过探测集群里的Node节点去判断各个Node所在机器上的MySQL运行是否正常
- 如果发现某个Master故障了,就直接把他的一个Slave提升为Master
- 然后让其他Slave都挂到新的Master上去,完全透明
- MHA是需要单独部署的,分为Manager节点和Node节点,两种节点
- 优点
- MHA除了支持日志点的复制还支持GTID的方式
- 同MMM相比,MHA会尝试从旧的Master中恢复旧的二进制日志,只是未必每次都能成功。如果希望更少的数据丢失场景,建议使用MHA架构
- 缺点
- MHA需要自行开发VIP转移脚本
- MHA只监控Master的状态,未监控Slave的状态
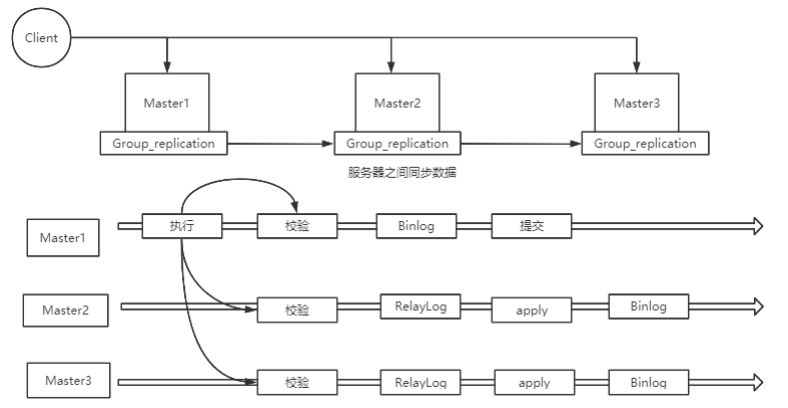
- MGR (MySQL Group Replication):官方组复制机制,解决传统异步复制和半同步复制的数据一致性问题
- 由若干个节点共同组成一个复制组,一个事务提交后,必须经过超过半数节点的决议并通过后,才可以提交
- MGR依靠分布式一致性协议(Paxos协议的一个变体),实现了分布式下数据的最终一致性,提供了真正的数据高可用方案
- 优点
- 高一致性
- 基于原生复制及paxos协议的组复制技术,并以插件的方式提供,提供一致数据安全保证
- 高容错性:只要不是大多数节点坏掉就可以继续工作
- 有自动检测机制,当不同节点产生资源争用冲突时,按照先到者优先原则进行处理
- 并且内置了自动化脑裂防护机制
- 高扩展性:节点的新增和移除都是自动的
- 新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致
- 如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息
- 高灵活性:有单主模式和多主模式(但官方推荐单主模式)
- 单主模式下,会自动选主,所有更新操作都在主上进行
- MGR集群会选出primary节点负责写请求
- primary节点与其它节点都可以进行读请求处理
- 多主模式下,所有server都可以同时处理更新操作
- 客户端可以随机向MySQL节点写入数据
- 单主模式下,会自动选主,所有更新操作都在主上进行
- 高一致性
- 缺点
- 仅支持InnoDB引擎,并且每张表一定要有一个主键,用于做write set的冲突检测
- 必须打开GTID特性,二进制日志格式必须设置为ROW,用于选主与write set;
- 主从状态信息存于表中
--master-info-repository=TABLE--relay-log-info-repository=TABLE
--log-slave-updates打开
- 主从状态信息存于表中
- COMMIT可能会导致失败,类似于快照事务隔离级别的失败场景
- 目前一个MGR集群最多支持9个节点
- 不支持外键于save point特性,无法做全局间的约束检测与部分事务回滚
- 适用场景
- 对主从延迟比较敏感
- 希望对写服务提供高可用,又不想安装第三方软件
- 数据强一致的场景
- 由若干个节点共同组成一个复制组,一个事务提交后,必须经过超过半数节点的决议并通过后,才可以提交
- 基于云原生的思路,完全可以让MySQL服务与数据物理分离,MySQL无状态自然就可以高可用
分库分表
- 垂直分片: 按照业务来对数据进行分片,又称为纵向分片(专库专用)
- 往往需要对架构和设计进行调整
- 通常来讲,是来不及应对业务需求快速变化的
- 无法真正的解决单点数据库的性能瓶颈
- 可以缓解数据量和访问量带来的问题,但无法根治
- 往往需要对架构和设计进行调整
- 水平分片:又称横向分片
- 常用的分片策略有
- 取余\取模:均匀存放数据;扩容非常麻烦
- 按照范围分片:比较好扩容;数据分布不够均匀
- 按照时间分片: 比较容易将热点数据区分出来
- 按照枚举值分片: 例如按地区分片
- 按照目标字段前缀指定进行分区:自定义业务规则分片
- 不需要数据迁移的取模分片扩容方案
- 共享内存中维护一个分片表
- 扩容后的数据路由直接查表
- 旧数据可以查表中之前的记录版本
- 数据均衡:动态加入的节点尽量多写数据
- 比如5个节点新增2个一共7个节点,可以按9取模,多的两个分配给新节点
- 共享内存中维护一个分片表
- 水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案
- 常用的分片策略有
- 一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库
- 在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案
- 若数据量极大,且持续增长,再考虑水平分库水平分表方案
- 分库分表要解决哪些问题
- 事务一致性问题
- 跨节点关联查询问题
- 跨节点分页、排序函数
- 主键避重问题
- 公共表处理
- 参数表、数据字典表等都是数据量较小,变动少,而且属于高频联合查询的依赖表
- 这一类表一般就需要在每个数据库中都保存一份,并且所有对公共表的操作都要分发到所有的分库去执行
- 运维工作量
- 什么时候需要分库分表
- MySQL单表记录如果达到500W这个级别
- 单表容量达到2GB
- 一般对于用户数据这一类后期增长比较缓慢的数据,一般可以按照三年左右的业务量来预估使用人数,按照标准预设好分库分表的方案
- 对于业务数据这一类增长快速且稳定的数据,一般则需要按照预估量的两倍左右预设分库分表方案
- 由于分库分表的后期扩容是非常麻烦的,所以在进行分库分表时,尽量根据情况,多分一些表
- 最好是计算一下数据增量,永远不用增加更多的表
- 在设计分库分表方案时,要尽量兼顾业务场景和数据分布
- 在支持业务场景的前提下,尽量保证数据能够分得更均匀
- 尽量在分库分表的同时,再补充设计一个降级方案
- 将数据转存一份到ES,ES可以实现更灵活的大数据聚合查询
- 常见的分库分表组件
- shardingsphere:Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar
- mycat
- DBLE



