- 五种数据结构:string hash list set zset
- 应用场景
- RedisTemplate 默认采用的是JDK的序列化,直接看的话key会有乱码,建议用 StringRedisTemplate
- IO多路复用
- SCAN
redisTemplate.opsForValue(); //操作字符串
redisTemplate.opsForHash(); //操作hash
redisTemplate.opsForList(); //操作list
redisTemplate.opsForSet(); //操作set
redisTemplate.opsForZSet(); //操作有序set数据结构
| 命令 | 参数 | 含义 | 代码 |
|---|---|---|---|
| STRING | ==STRING== | RedisTemplate rt | |
| SET | key value | 存入字符串键值对 | rt.opsForValue().set(“key”,“value”) |
| MSET | key value [key value …] | 批量存入字符串键值对 | |
| SETNX | key value | 存入一个不存在的字符串键值对 | |
| GET | key | 获取字符串键值 | rt.opsForValue().get(“key”) |
| MGET | key [key …] | 批量获取字符串键值 | |
| DEL | key [key …] | 删除一个键 | rt.delete(“key”) |
| EXPIRE | key seconds | 设置一个键的过期时间(秒) | |
| INCR | key | 原子 +1 | |
| DECR | key | 原子 -1 | |
| INCRBY | key num | 原子 +num | |
| DECRBY | key num | 原子 -num | |
| STRLEN | key | rt.opsForValue().size(“key”) | |
| GETSET | key value | rt.opsForValue().getAndSet(“key”,“value”) | |
| GETRANGE | key start end | rt.opsForValue().get(“key”,start,end) | |
| APPEND | key value | rt.opsForValue().append(“key”,“value”) | |
| HASH | ==HASH== | ||
| HSET | key field value | 存入一个哈希表key的键值 | rt.opsForHash().put(“key”,“field”,“value”) |
| HSETNX | key field value | 存入一个不存在的哈希表key的键值 | rt.opsForHash().putIfAbsent(“key”,“field”,“value”) |
| HMSET | key field value [field value …] | 在一个哈希表key中存入多个键值对 | rt.opsForHash().putAll(“key”,map) |
| HGET | key field | 获取哈希表key对应的field键值 | rt.opsForHash().get(“key”,“field”) |
| HMGET | key field [field …] | 批量获取哈希表key中多个field键值 | rt.opsForHash().multiGet(“key”,fieldList) |
| HDEL | key field [field …] | 删除哈希表key中的field键值 | rt.opsForHash().delete(“key”,“field1”,“field2”) |
| HLEN | key | 返回哈希表key中field的数量 | |
| HGETALL | key | 返回哈希表key中所有的键值 | rt.opsForHash().entries(“key”) |
| HINCRBY | key field num | 为哈希表key中field键的值原子 +num | |
| HEXISTS | key field | rt.opsForHash().hasKey(“key”,“field”) | |
| HVALS | key | rt.opsForHash().values(“key”) | |
| HKEYS | key | rt.opsForHash().keys(“key”) | |
| LIST | ==LIST== | ||
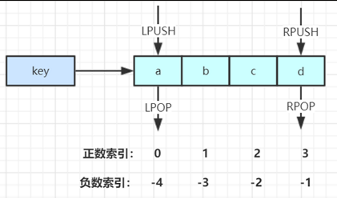
| LPUSH | key value [value …] | 插入到列表的表头(最左边) | rt.opsForList().leftPush(“key”,“value”) rt.opsForList().leftPushAll(“key”,valueList) |
| RPUSH | key value [value …] | 插入到列表的表尾(最右边) | rt.opsForList().rightPush(“key”,“value”) rt.opsForList().rightPushAll(“key”,valueList) |
| LPOP | key | 移除并返回key列表的头元素 | rt.opsForList().leftPop(“key”) |
| RPOP | key | 移除并返回key列表的尾元素 | rt.opsForList().rightPop(“key”) |
| LRANGE | key start stop | 返回列表key中 start-stop 区间内的元素 | rt.opsForList().range(“key”,start,end) |
| BLPOP | key [key …] timeout | 从列表表头弹出一个元素,若没有则阻塞等待timeout秒,如果timeout=0,则一直等待 | |
| BRPOP | key [key …] timeout | 从列表表尾弹出一个元素,若没有则阻塞等待timeout秒,如果timeout=0,则一直等待 | |
| LINDEX | key index | rt.opsForList().index(“key”, index) | |
| LLEN | key | rt.opsForList().size(“key”) | |
| LPUSHX | list node | rt.opsForList().leftPushIfPresent(“list”,“node”) | |
| RPUSHX | list node | rt.opsForList().rightPushIfPresent(“list”,“node”) | |
| LREM | list count value | rt.opsForList().remove(“list”,count,“value”) | |
| LSET | key index value | rt.opsForList().set(“list”,index,“value”) | |
| SET | ==SET== | ||
| SADD | key member [member …] | 往集合key中存入元素,元素存在则忽略 | rt.boundSetOps(“key”).add(“member1”,…) rt.opsForSet().add(“key”, set) |
| SREM | key member [member …] | 从集合key中删除元素 | rt.opsForSet().remove(“key”,“member1”,…) |
| SMEMBERS | key | 获取集合key中所有元素 | rt.opsForSet().members(“key”) |
| SCARD | key | 获取集合key的元素个数 | rt.opsForSet().size(“key”) |
| SISMEMBER | key member | 判断member元素是否存在于集合key中 | rt.opsForSet().isMember(“key”,“member”) |
| SRANDMEMBER | key [count] | 从集合key中选出count个元素,元素不从key中删除 | rt.opsForSet().randomMember(“key”,count) |
| SPOP | key [count] | 从集合key中选出count个元素,元素从key中删除 | rt.opsForSet().pop(“key”) |
| SINTER | key [key …] | 交集运算 | rt.opsForSet().intersect(“key1”,“key2”) |
| SINTERSTORE | destination key [key …] | 将交集结果存入新集合destination中 | rt.opsForSet().intersectAndStore(“key1”,“key2”,“des”) |
| SUNION | key [key …] | 并集运算 | rt.opsForSet().union(“key1”,“key2”) |
| SUNIONSTORE | destination key [key …] | 将并集结果存入新集合destination中 | rt.opsForSet().unionAndStore(“key1”,“key2”,“des”) |
| SDIFF | key [key …] | 差集运算 | rt.opsForSet().difference(“key1”,“key2”) |
| SDIFFSTORE | destination key [key …] | 将差集结果存入新集合destination中 | rt.opsForSet().differenceAndStore(“key1”,“key2”,“des”) |
| ZSET | ==ZSET== | ||
| ZADD | key score member [[score member]…] | 往有序集合key中加入带分值元素 | |
| ZREM | key member [member …] | 从有序集合key中删除元素 | |
| ZSCORE | key member | 返回有序集合key中元素member的分值 | |
| ZINCRBY | key num member | 为有序集合key中元素member的分值原子 +num | |
| ZCARD | key | 返回有序集合key中元素个数 | |
| ZRANGE | key start stop [WITHSCORES] | 正序获取有序集合key从start下标到stop下标的元素 | |
| ZREVRANGE | key start stop [WITHSCORES] | 倒序获取有序集合key从start下标到stop下标的元素 | |
| ZUNIONSTORE | destkey numkeys key [key …] | 并集计算 | |
| ZINTERSTORE | destkey numkeys key [key …] | 交集计算 |
应用场景
- STRING 应用场景
- 单值缓存 | 对象缓存(Session共享)
- 分布式锁:SET product:10001 true ex 10 nx
- 计数器(分布式唯一ID,客户端批量获取,缺点:断电导致重复ID)
- HASH 应用场景
- 对象缓存(大KEY问题)
- 购物车:用户id为key;商品id为field;商品数量为value
- 优点
- 同类数据归类整合储存,方便数据管理
- 相比string操作消耗内存与cpu更小
- 相比string储存更节省空间
- 缺点
- 过期功能不能使用在field上,只能用在key上
- Redis集群架构下不适合大规模使用
- LIST 应用场景
- 社交平台发文(时间顺序展示)
- 数据结构
- 栈 = LPUSH + LPOP
- 队列 = LPUSH + RPOP
- 阻塞队列 = LPUSH + BRPOP
- SET 应用场景
- 抽奖:SADD / SRANDMEMBER / SPOP / SMEMBERS
- 点赞:SADD / SREM / SISMEMBER / SMEMBERS / SCARD / SINTER
- 关注模型
- 共同关注:SINTER
- 我关注的人也关注他:SISMEMBER
- 可能认识的人(朋友的朋友 - 我的朋友):SDIFF
- 商品筛选(多查询条件取交集):SINTER
- ZSET 应用场景
- 新闻排行榜
- 点击:ZINCRBY hotNews:20190819 1 xxx文章
- 前十:ZREVRANGE hotNews:20190819 0 9 WITHSCORES
- 七日榜单:ZUNIONSTORE hotNews:20190813-20190819 7
- 七日前十:ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
- 新闻排行榜
IO多路复用
- 单线程:
- Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的
- 因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。正因为 Redis 是单线程,所以要小心使用耗时的指令(比如keys),一不小心就可能会导致 Redis 卡顿
- Redis的IO多路复用:
- redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器
- 查看redis支持的最大连接数,在redis.conf文件中可修改:
CONFIG GET maxclients - SCAN
- KEYS是全量遍历,当数据量大时,性能很差,应用 SCAN 取代(手动分段遍历,直到游标为0停止遍历)
SCAN 0 match jxch** count 100- 以0为游标,分段扫描以jxch开头的key,每次返回100个,然后以返回值为游标,继续扫描,直到返回的游标为0
- 注意,100是个参考值,实际返回的是接近100的数目,可能多也可能少(取决于HASH桶中有几个值,因为Redis的存储结构是哈希表)
- 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那么遍历效果可能会碰到如下问题
- 新增的键可能没有遍历到(不会扫描已经遍历过的HASH桶)
- 遍历出了重复的键(发生了RE-HASH)
- SCAN并不能保证完整的遍历出来所有的键, 这些是我们在开发时需要考虑的,但在追求性能的情况下,往往并不要求一致性



