发布日期:
2024-09-10
文章字数:
612
阅读时长:
2 分
阅读次数:
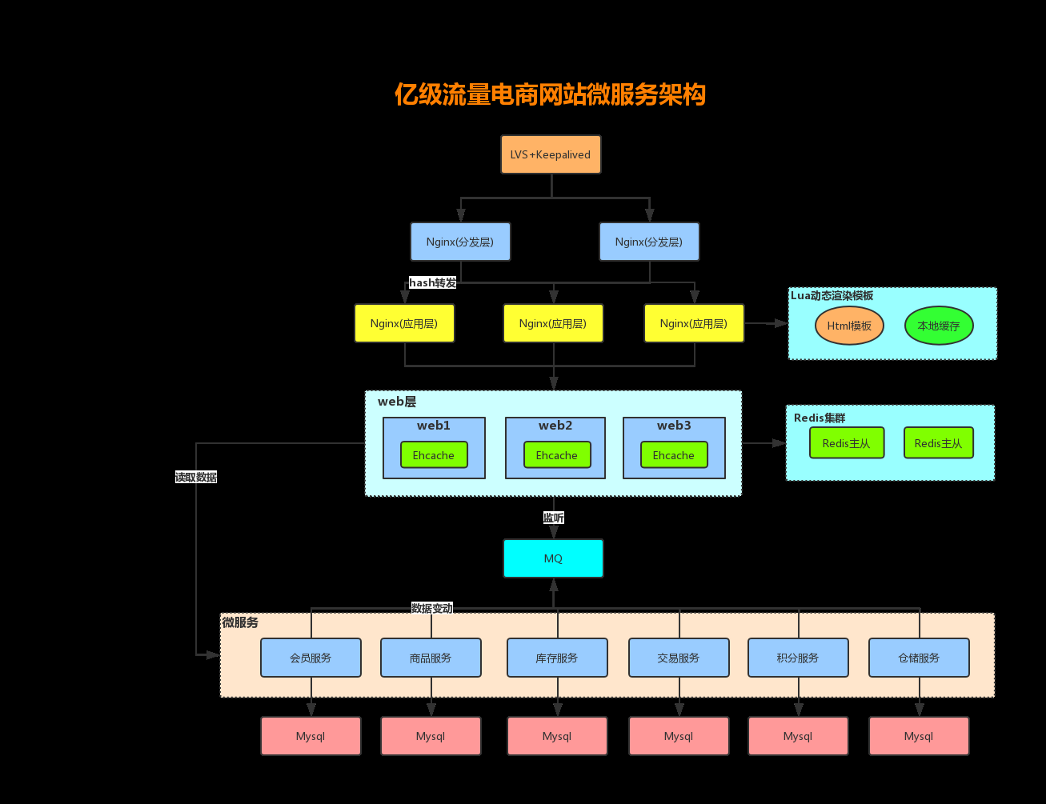
- 缓存击穿&缓存穿透&缓存雪崩
- 热点KEY的缓存重建
- 双写不一致&读写并发不一致
- 写多读多
- 缓存击穿:缓存集体失效导致某一时刻大量请求打到数据库
- 随机缓存失效时间
- 读延期:阻塞该数据的访问,直到缓存重新建立
- 缓存穿透:请求数据库不存在的数据(缓存肯定也不存在)
- 恶意攻击,并发请求不存在的商品ID,导致数据库宕机
- 布隆过滤器:返回不存在则一定不存在,只能添加不能更新(定期重新初始化)
- 缓存空对象并设置失效时间(避免缓存被长时间占满):避免布隆过滤器哈希碰撞
- 缓存雪崩:缓存层宕机或无法正常提供服务(超大并发)
- 热点中的热点导致超大并发请求:本地缓存(多级缓存)
- 热点探测系统维护缓存内容并通知更新本地缓存 :分布式大数据实时计算
- MQ或ZK通知更新本地缓存:数据短暂不一致,增加系统复杂度
- 服务层限流熔断降级
- 提高缓存层可用性
- 提前压测
- 热点KEY的缓存重建 & 冷门商品突然变热:大量线程同时重建缓存导致数据库宕机
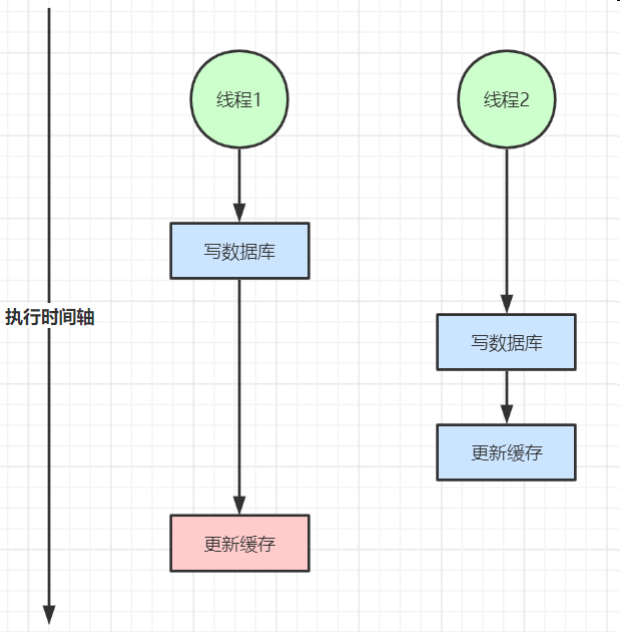
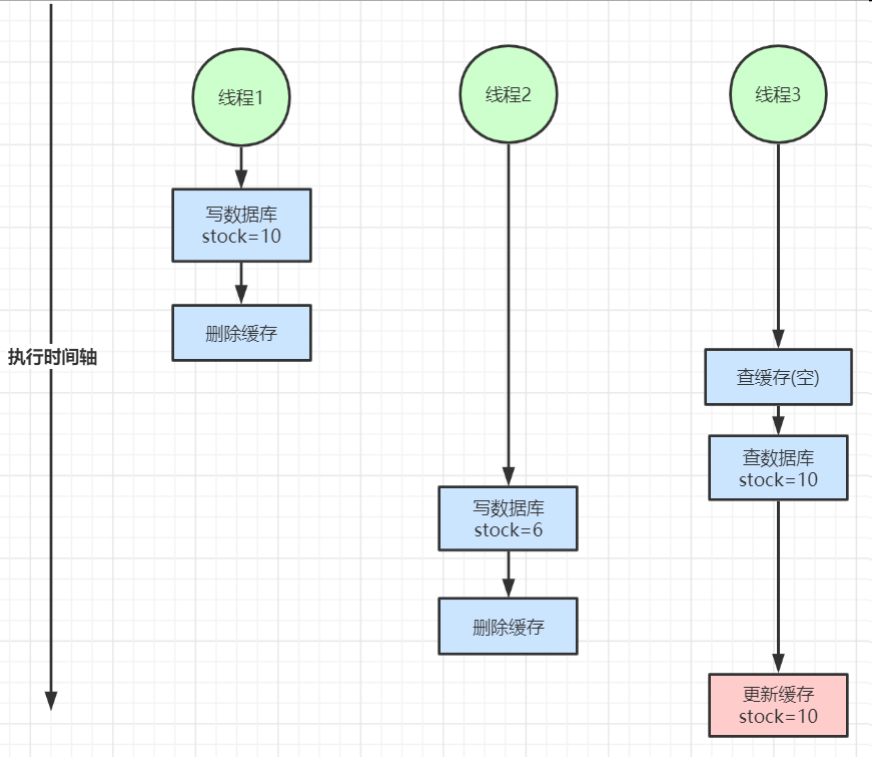
- 缓存数据不一致:ABA问题
- 缓存与数据库双写不一致
- 读写并发不一致(发生概率偏低,因为查的速度一般快于写)
- 解决方案
- 写库和查库(重建缓存)之前使用分布式读写锁
- 延时双删:写库后延时删两次缓存,不推荐用这种方式解决小概率事件浪费大量性能
- canal:模拟MySQL从库监听binlog,更新缓存,引入中间件增加了系统复杂性
- 写多读多场景
- MQ直接操作数据库
- 缓存作为主存储,异步同步到数据库
- 放入缓存的数据应该是对实时性、一致性要求不是很高的数据。切记不要为了用缓存,同时又要保证绝对的一致性做大量的过度设计和控制,增加系统复杂性!