- Redis 应用场景
- Redis 底层核心数据结构
- Redis 渐进式rehash及动态扩容机制
- BitMap 海量数据统计
- GeoHash 经纬度计算
Redis 应用场景
- 缓存
- 计数器:可以对 String 进行自增自减运算,从而实现计数器功能。Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量
- 分布式ID生成(宕机后ID重复):利用自增特性,一次请求一个大一点的步长如 incr 2000 ,缓存在本地使用,用完再请求
- 海量数据统计 - 位图(bitmap)::存储是否参过某次活动,是否已读谋篇文章,用户是否为会员, 日活统计。
- 会话缓存:可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性
- 分布式队列/阻塞队列:List 是一个双向链表,可以通过 lpush/rpush 和 rpop/lpop 写入和读取消息。可以通过使用brpop/blpop 来实现阻塞队列
- 分布式锁实现:在分布式场景下,无法使用基于进程的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX 命令实现分布式锁
- 热点数据存储:最新评论,最新文章列表,使用list 存储,ltrim取出热点数据,删除老数据
- 社交类需求:Set 可以实现交集,从而实现共同好友等功能,Set通过求差集,可以进行好友推荐,文章推荐
- 排行榜:sorted_set可以实现有序性操作,从而实现排行榜等功能
- 延迟队列:使用sorted_set,使用 【当前时间戳 + 需要延迟的时长】做score, 消息内容作为元素,调用zadd来生产消息,消费者使用zrangbyscore获取当前时间之前的数据做轮询处理。消费完再删除任务
rem key member
Redis 底层核心数据结构
String
- Redis 的字符串类型使用
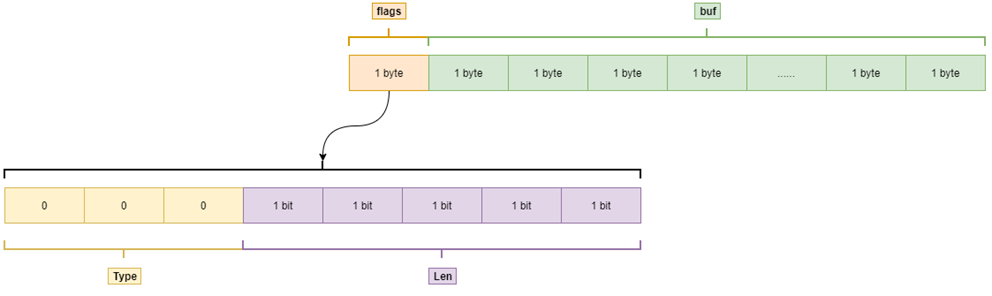
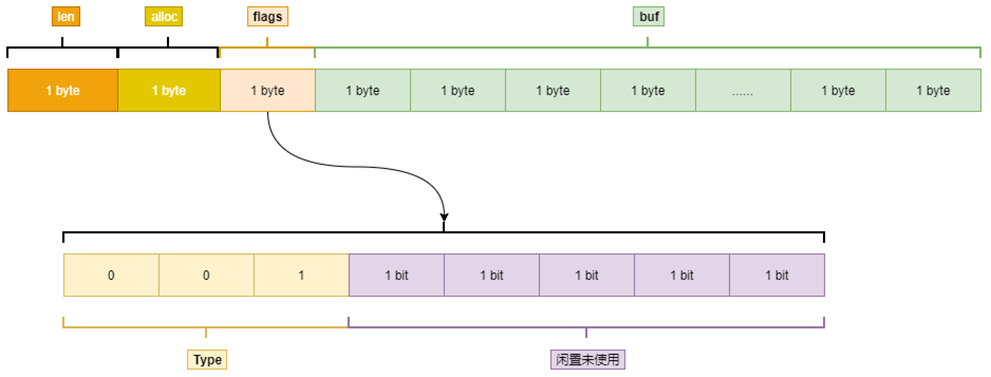
SDS(Simple Dynamic String) 作为其底层实现- 预分配策略
- 减少内存重新分配次数,提高性能,SDS 会在字符串增长时预先分配多余的空间
- 空间缩减策略
- 当字符串缩短或者释放时,SDS 并不会立即释放多余的空间,这样可以保留一些预分配的内存以供将来使用
- 对于短字符串,SDS 会预先分配一小段过量的空间
- 对于长字符串,预分配的空间比例会减少,但依然会多分配一定比例的内存
- 预分配策略
List
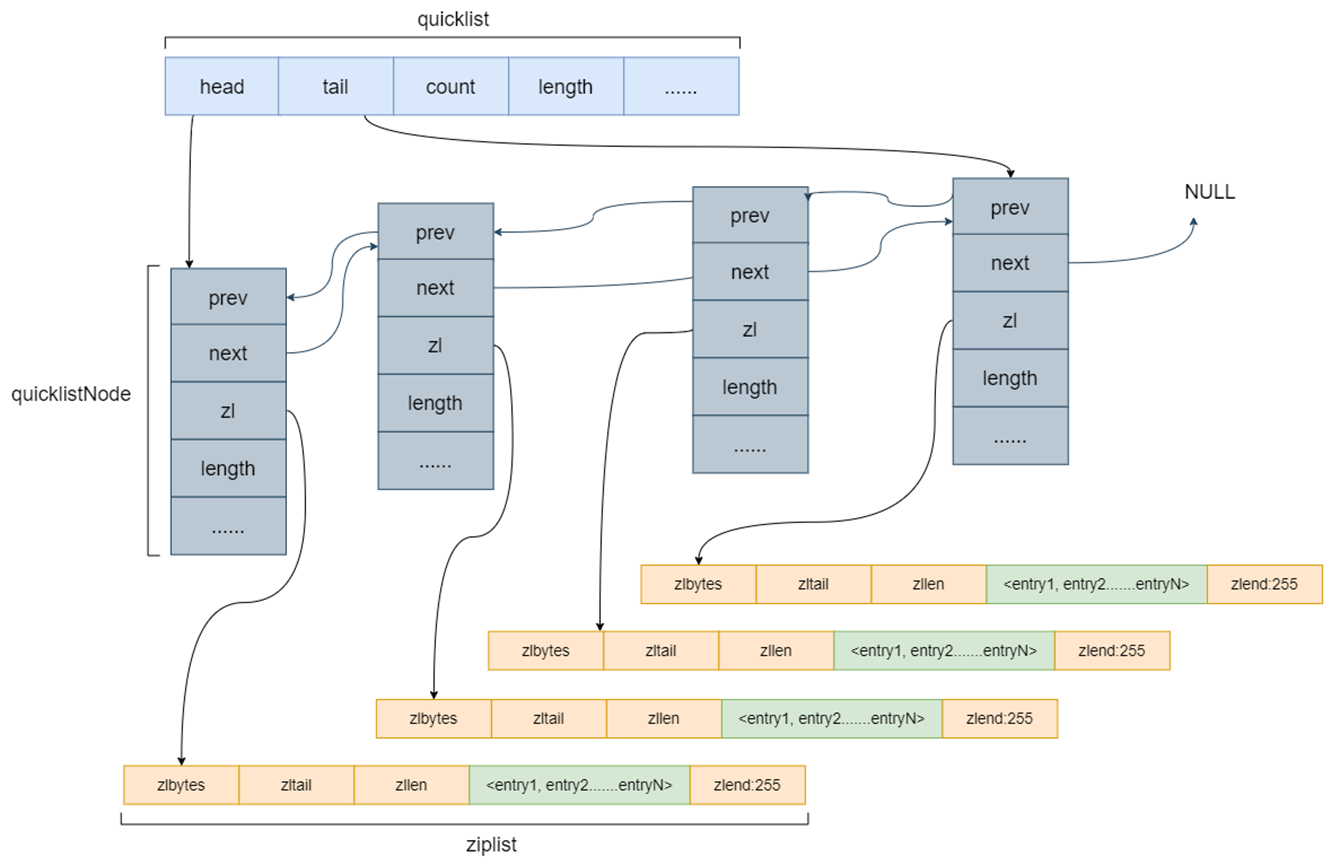
- 采用 quicklist(双端链表) 和 ziplist 作为 List 的底层实现
- list-max-ziplist-size -2
- 单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中
- list-compress-depth 1
- 0 代表所有节点,都不进行压缩,1, 代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4 … 以此类推
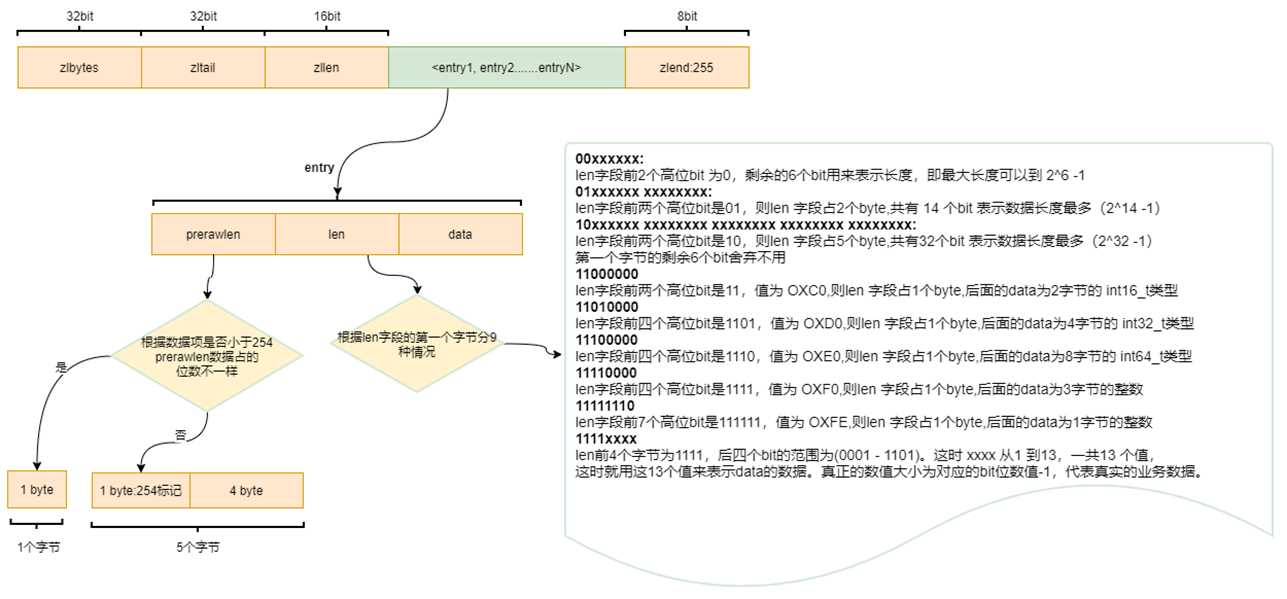
- ziplist
- 紧凑存储
ziplist通过连续分配一段内存块,紧凑存储多个元素,以减少内存开销- 每个元素包括实际数据以及前序长度和当前长度的元数据,而非像
linkedlist一样每个元素都包含独立的指针
- 预分配和回收空间
ziplist并不具备类似SDS的空间预分配机制,但在插入和删除元素时会重新分配内存- 如果新插入的元素使得现有内存不足,
ziplist会重新分配足够的内存来容纳新的数据
- 数据结构
ziplist由多部分组成:起始偏移量、数据节点、结尾标志等- 每个数据节点由前向长度(prevlen)、编码和实际数据组成
- 节点之间通过偏移量而非指针联系,这使得
ziplist更紧凑,但插入和删除操作相对复杂,因为需要移动大量数据
- 内存复制和移动
- 因为
ziplist是一块连续内存,在插入或删除元素时需要进行内存复制和移动操作,这会影响性能,特别是在元素较多的情况下 -
- 当列表增大到一定程度,Redis 会自动将其转换为更合适的数据结构
- 因为
- 使用场景
- 小数据量:
ziplist适用于小型数据结构(小列表和小哈希)。它能够有效减少内存开销,并且在数据量较小的情况下,其操作效率也较高 - 内存敏感:在内存敏感的场景中,
ziplist可以提供良好的内存使用效率
- 小数据量:
- 限制条件
list-max-ziplist-entries和list-max-ziplist-value,分别限制了列表中节点的最大数量和节点值的最大长度,当ziplist超过这些限制时,Redis 会将其转换为其他数据结构
- 紧凑存储
Hash
- 底层实现为一个字典( dict )
- 当数据量比较小,或者单个元素比较小时,底层用ziplist存储
- hash-max-ziplist-entries 512
- ziplist 元素个数超过 512 ,将改为hashtable编码
- hash-max-ziplist-value 64
- 单个元素大小超过 64 byte时,将改为hashtable编码

Set
- 底层实现为一个value 为 null 的 字典( dict )
- 当数据可以用整形表示时,Set集合将被编码为intset数据结构
- 两个条件任意满足时Set将用hashtable存储数据
- 元素个数大于 set-max-intset-entries
- set-max-intset-entries 512
- intset 能存储的最大元素个数,超过则用hashtable编码
- set-max-intset-entries 512
- 元素无法用整形表示
- 元素个数大于 set-max-intset-entries
- intset
- 整数集合是一个有序的,存储整型数据的结构
- 整型集合在Redis中可以保存int16_t,int32_t,int64_t类型的整型数据
- 可以保证集合中不会出现重复数据

ZSet
- 有序的,自动去重的集合数据类型
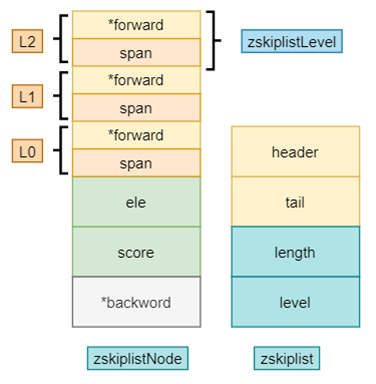
- 底层实现为 字典(dict) + 跳表(skiplist)
- 字典用于快速进行元素唯一性判定,而 Skiplist 用于保持元素的有序排列。每个元素同时存在于字典和 Skiplist 中,这样保证了两种数据结构的优势
- 当数据比较少时,用ziplist编码结构存储
- zset-max-ziplist-entries 128
- 元素个数超过128,将用skiplist编码
- zset-max-ziplist-value 64
- 单个元素大小超过 64 byte,将用 skiplist编码

- skiplist
- 多级链表
- Skiplist 由多层链表组成,每层链表都是底层链表的子集。底层链表包含所有元素,而每一层链表以一定概率抽取上层的一部分节点
- 每个节点包含多个指向下一层节点的指针,指针数量与节点所在层数相关
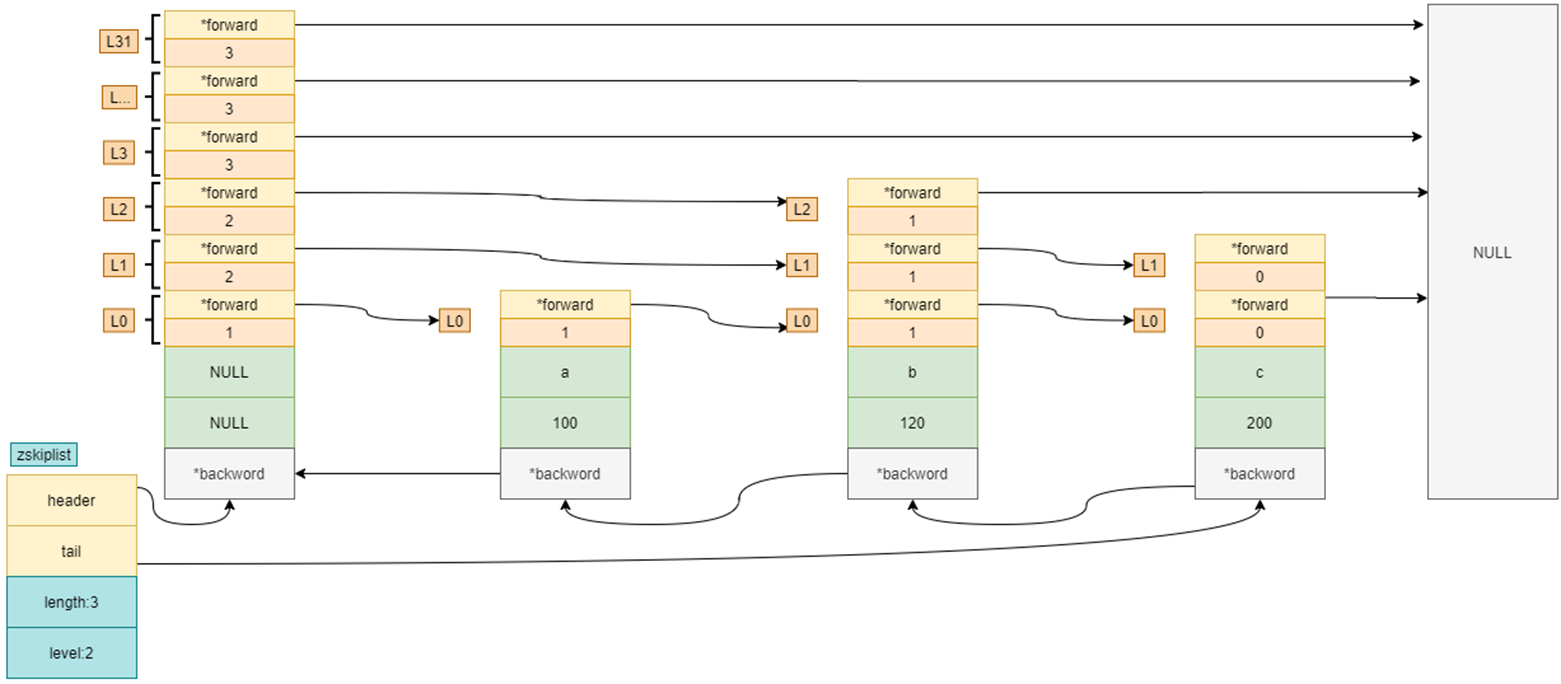
- 随机层数
- 插入新元素时,会随机决定新节点的层数。通常使用几何分布来确定层数,这样每个节点以一定概率加入更高层。从而保证了平均情况下查询操作的时间复杂度是对数级的
- Redis 中,使用 1/4 的概率选择更高层,所以每层链表中的元素期望数量是其下层链表的 1/4
- 查找操作
- 查找过程从顶层链表开始,逐层向下进行
- 在每一层,查找操作按顺序走链表,直到找到目标元素或者需要进入下一层
- 因为更高层链表中的元素较少,查找操作在平均情况下是 O(log n) 的复杂度
- 插入和删除操作
- 插入操作先进行查找,找到插入位置后,根据随机层数将新节点插入相应层
- 删除操作类似,先进行查找,找到目标节点后,更新相关指针进行删除
- 虽然最坏情况下时间复杂度是 O(n),但由于层级结构和随机分布,平均性能表现为 O(log n)
- 多级链表
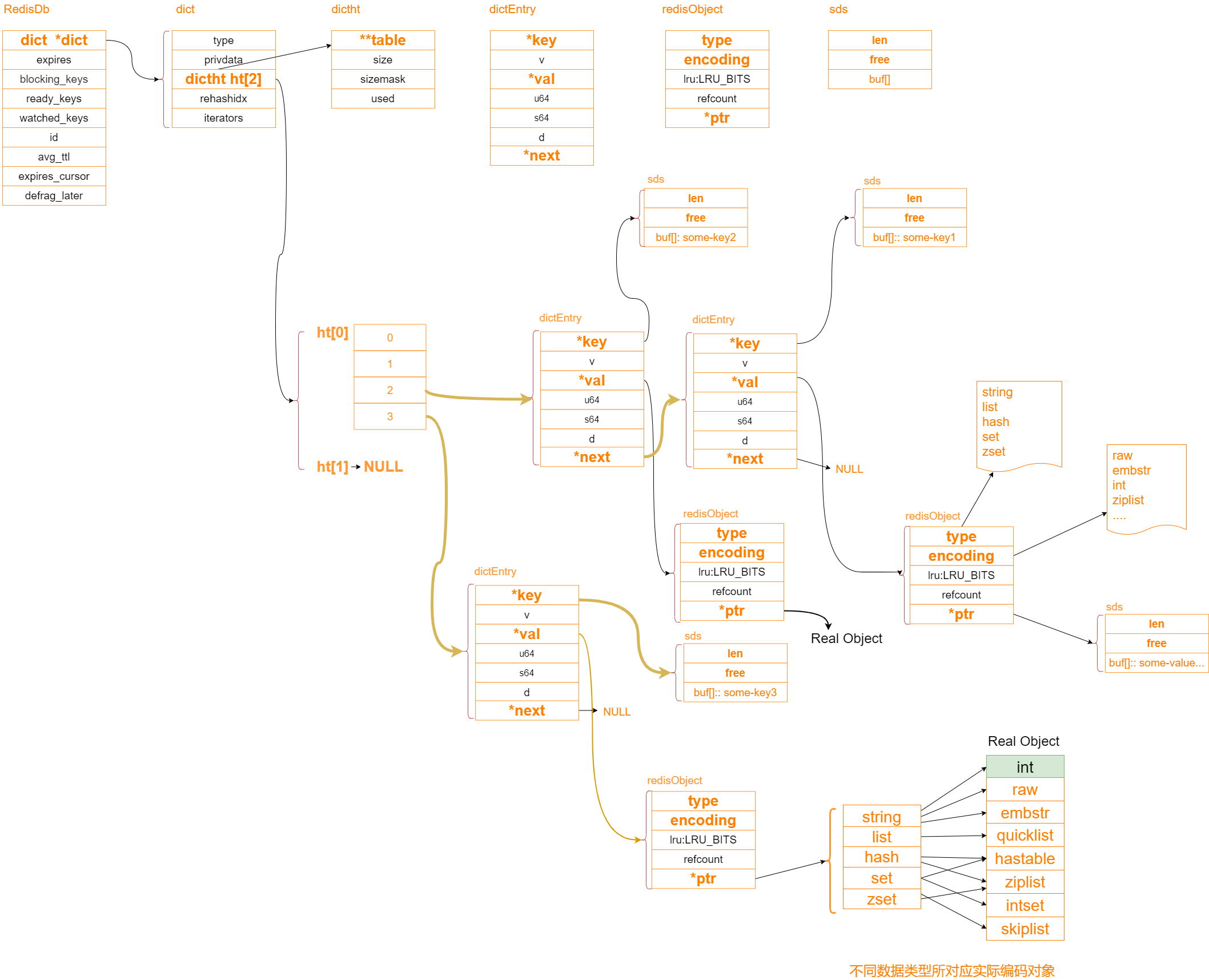
- 渐进式rehash及动态扩容机制:避免在一次性rehash操作过程中导致大规模停顿
- Redis的数据结构字典(dict)中存在两个哈希表
ht[0]和ht[1]- 其中
ht[0]用于存储当前数据,当开始rehash时,会初始化ht[1]并逐步将ht[0]中的数据迁移到ht[1]
- 其中
- Redis检测到需要扩展或收缩哈希表时,会初始化一个新的哈希表
ht[1],其大小根据需要进行扩展或收缩 - 设置一个标志,表示当前正在进行rehash操作
- 逐步迁移数据:在每次对字典进行增删查改等普通操作时,Redis会将有限数量(如一个或多个)从旧的哈希表
ht[0]迁移到新的哈希表ht[1]中。这些操作包括get,set,del等 - 在rehash进行期间,所有的查找、插入操作都会同时对
ht[0]和ht[1]生效。如果一个键在ht[0]中不存在,则继续查找ht[1] - 当
ht[0]的所有数据全部迁移到ht[1]后,删除旧哈希表ht[0],并将ht[1]设置为新的数据哈希表
- Redis的数据结构字典(dict)中存在两个哈希表
- 尽管渐进式rehash极大地提高了Redis的实时性和性能,但在rehash过程中,哈希表的大小并不会立即固定,这可能导致一些特殊情况下的查询延迟增加
active-rehashing参数决定是否在后台进程中主动进行rehash操作,也可以在主操作线程中逐步完成rehash,以使得逐步迁移在后端缓解表操作压力
- BitMap :本质是字符串
- GETBIT/SETBIT/BITOPS/BITCOUNT
- 连续登录统计,每天的bitmap进行与运算
GeoHash 经纬度计算
- 将地理位置编码为一串简短的字母和数字
- 将空间细分为网格形状的桶,这是所谓的z顺序曲线的众多应用之一,通常是空间填充曲线
- 经纬度编码
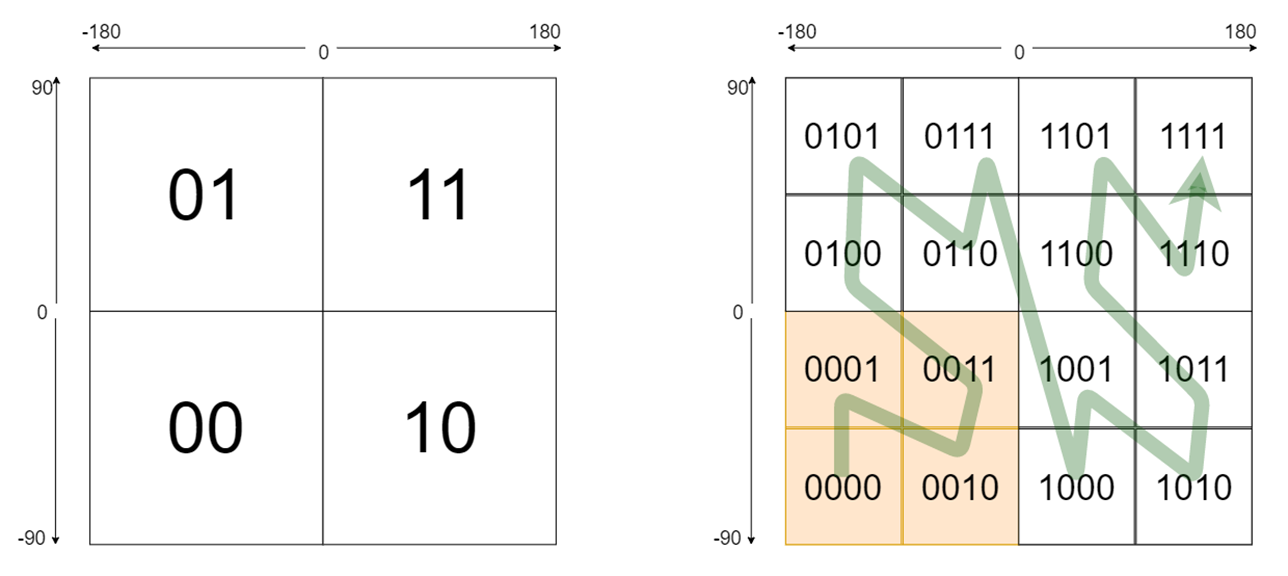
- 经度范围是东经180到西经180,纬度范围是南纬90到北纬90
- 设定西经为负,南纬为负,所以地球上的经度范围就是
[-180, 180],纬度范围就是[-90,90] - 如果以本初子午线、赤道为界,地球可以分成4个部分
- 设定西经为负,南纬为负,所以地球上的经度范围就是
- 如果纬度范围
[-90°, 0°)用二进制0代表,(0°, 90°]用二进制1代表,经度范围[-180°, 0°)用二进制0代表,(0°, 180°]用二进制1代表,那么地球可以分成如下(左图 )4个部分
- 经度范围是东经180到西经180,纬度范围是南纬90到北纬90
- 通过GeoHash算法,可以将经纬度的二维坐标变成一个可排序、可比较的的字符串编码
- 每个字符代表一个区域,并且前面的字符是后面字符的父区域
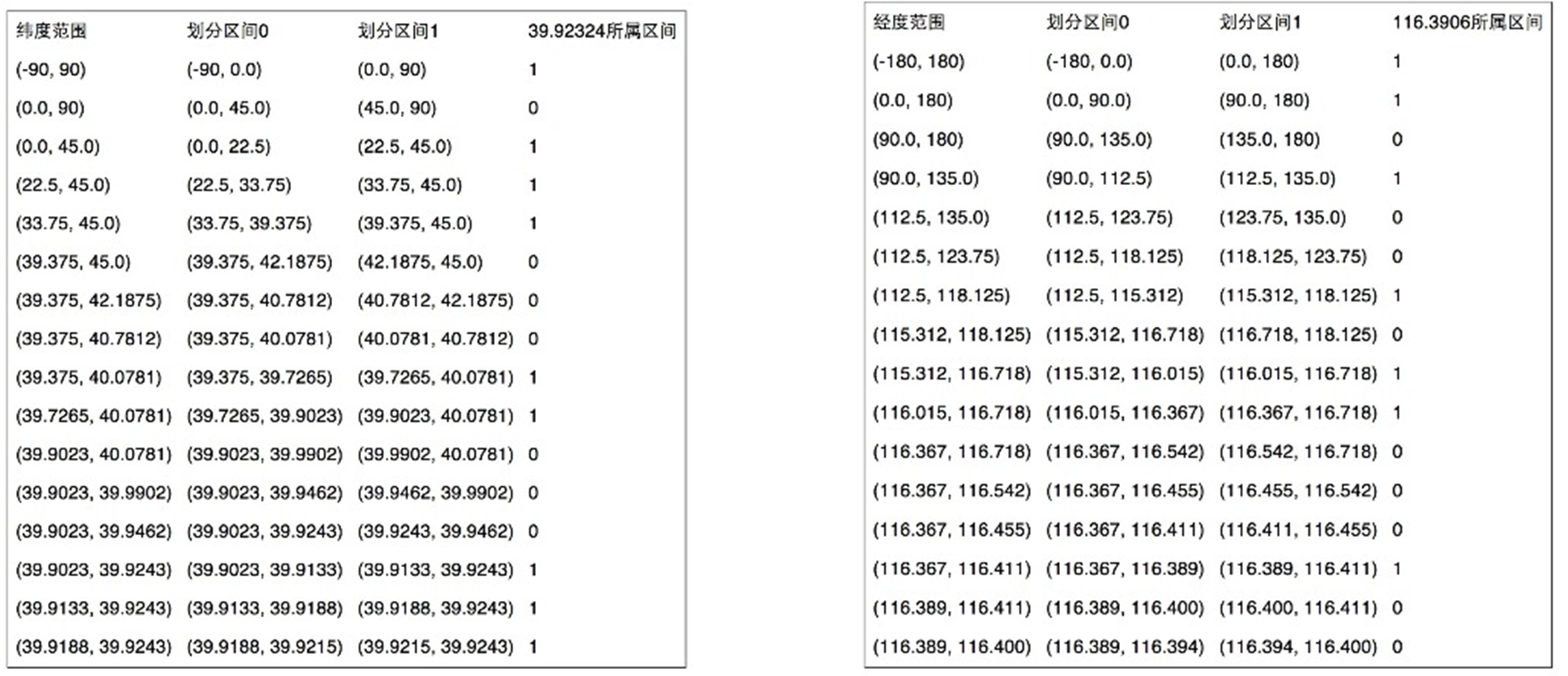
- 纬度产生的编码为1011 1000 1100 0111 1001,经度产生的编码为1101 0010 1100 0100 0100
- 偶数位放经度,奇数位放纬度,把2串编码组合生成新串 11100 11101 00100 01111 00000 01101 01011 00001
- 最后使用用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码(将编码转换成经纬度的解码算法与之相反)
- 首先将11100 11101 00100 01111 00000 01101 01011 00001转成十进制 28,29,4,15,0,13,11,1
- 十进制对应的编码就是wx4g0ec1
- 优点
- GeoHash利用Z阶曲线进行编码,Z阶曲线可以将二维所有点都转换成一阶曲线。地理位置坐标点通过编码转化成一维值,利用有序数据结构如B树、SkipList等,均可进行范围搜索。因此利用GeoHash算法查找邻近点比较快
- 缺点
- Z 阶曲线有一个比较严重的问题,虽然有局部保序性,但是它也有突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变