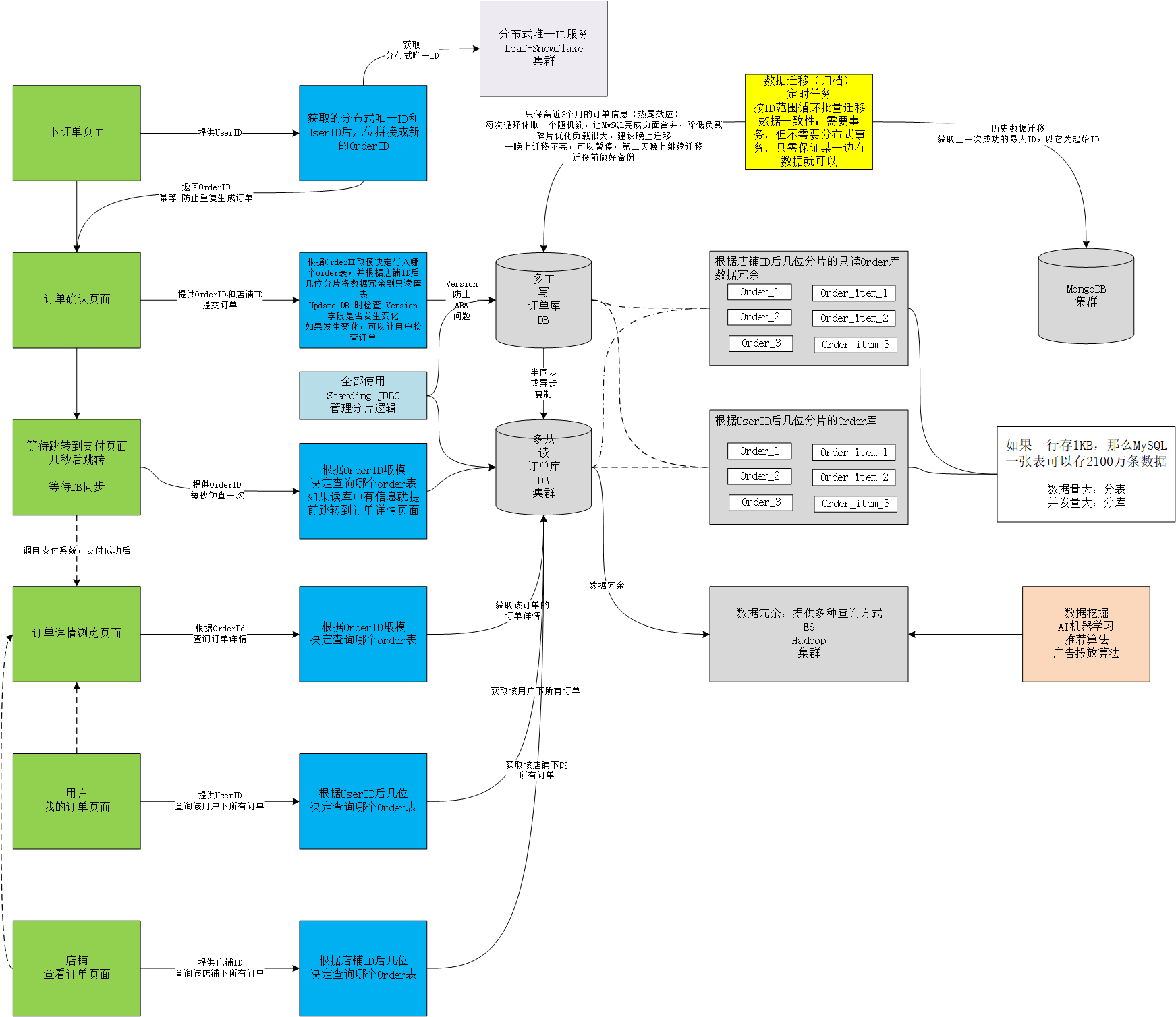
幂等
一件事情做几次结果都一样(防止用户提交两次订单)
唯一性索引:生成订单ID的操作提前到核对订单页面并在页面携带此ID,提交订单时直接使用此ID
ABA问题(使用版本号):
如用户修改订单详情,物品颜色(更新订单信息的ABA问题):
- 红色,修改成功,网络响应失败(触发重试)
- 绿色,用户修改成功
- 红色,重试成功
用户想要的是第二次修改的绿色,最后结果确是红色
使用版本号解决这个问题:update db时检查 version 有没有发生变化
读写分离
我的订单中,每个用户的订单都不同,所以不能用 redis 缓存数据,只能用读写分离优化查询速度
存在主从同步时数据暂时的不一致情况,可以插入支付成功页面,几秒后跳转详情页面,然后从读库查询
在要求较高的业务场景下可以在同一事务中,在写库写完就在写库读然后返回给前端
分库分表
能少拆就少拆,能不拆就不拆,降低维护复杂度
在MySQL中,如果一行存1kb的数据,那么一张表可以在不影响性能的情况下,大概存储2100条数据
数据量大:分表
并发量大:分库
分表分片策略
按时间或按ID取模等
- 根据orderid mod缺陷:无法根据userid查询该用户下的所有订单
- 解决方案:根据 orderid 和 userid 后几位拼接一个新的 orderid(基因法),然后 mod 取模
- 缺陷:无法根据店铺ID查询该店铺下的所有订单
- 解决方案 - 数据冗余:订单数据同步到其他存储,比如ES,Hadoop或MySQL(以店铺ID作为分片键的只读订单库)等
- 缺陷:无法根据店铺ID查询该店铺下的所有订单
- 解决方案:根据 orderid 和 userid 后几位拼接一个新的 orderid(基因法),然后 mod 取模
实现方案
- Sharding-JDBC(推荐使用)
- 代理方式(MyCat,好久不更新了):使用起来最简单
- 缺陷:性能损失较大,需要两次请求
- 历史订单归档(数据迁移,根据热尾效应,只保留近3个月的数据,提高提高表的查询速度)
- 定时任务:MySQL -> MongoDB
- 循环批量插入(mysql delete,mongodb insert)
- 数据库负载很大,MySQL可以按ID范围删除(每次2000条),每次循环休眠一个随机数,让MySQL完成页面合并,降低负载
- 碎片优化负载很大,建议晚上迁移,一晚上迁移不完,可以暂停,第二天晚上继续迁移
- 迁移前做好备份
- 数据一致性:需要事务,但不需要分布式事务
- 获取上一次成功的最大ID,以它为起始ID:只需保证某一边有数据就可以
- 定时任务:MySQL -> MongoDB



