为什么需要分布式唯一ID而不是UUID:因为数据库存储采用B树(有序),无序数据导致B树不断旋转
所有业务都需要分布式唯一ID吗?订单主表:全局唯一;订单详情表:1. 不需要全局唯一;2. 一次性获取所有ID
方案(推荐 Leaf-Snowflake)
- 雪花算法(1bit + timestamp(41bit) + workid(机房号5bit+机器号5bit) + 序列号12bit)
- 缺陷:时钟回拨导致ID重复
- Mongdb: objeckID
- Seata: UUID: IdWorker
- 数据库,一张表专门生成ID(累加,mysql: replace into;Oracle: sequence)
- 缺陷:IO并发量太低,可以使用多台服务器,为了保证不重复,可以让第一台奇数,第二台偶数
- 缺陷:水平扩容复杂
- 缺陷:IO并发量太低,可以使用多台服务器,为了保证不重复,可以让第一台奇数,第二台偶数
- redis(incr)
- 缺陷:断电故障(持久化是异步的)
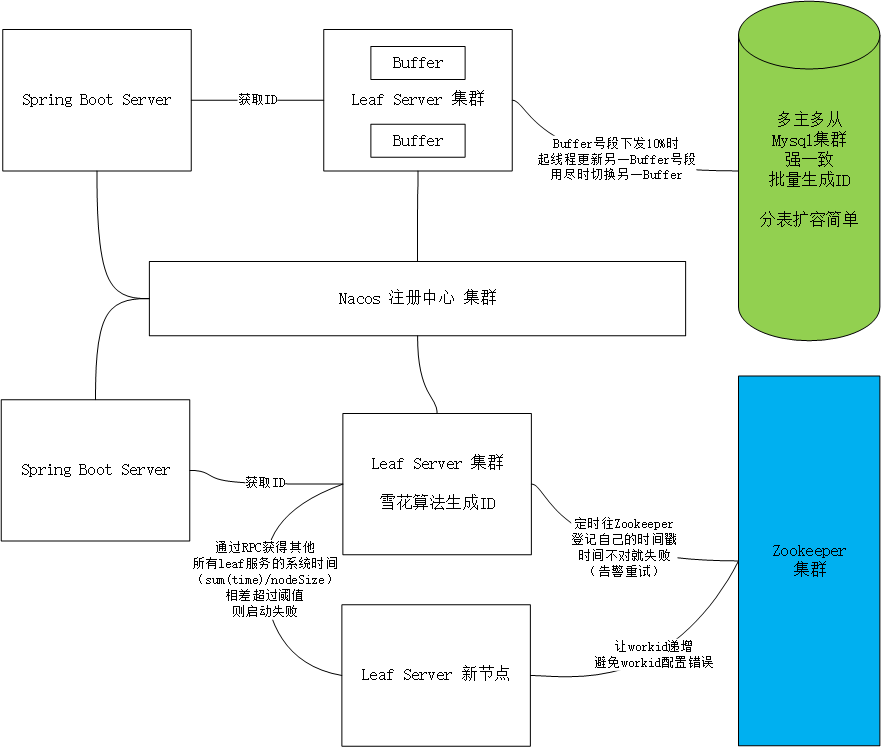
- Leaf-Segment(mysql数据表用于记录自定义批量生成的ID)
- 缺陷:批量的,id不随机,数据量会被猜到
- 解决毛刺现象:双缓存优化(日常用量的600倍,mysql宕机有10-20分钟重启)
- 高可用:mysql强一致,MGR - Paxos算法
- Leaf-Snowflake(雪花 + zookeeper,避免数据量被猜到)
- 使用zookeeper,让workid递增,避免workid配置错误
- 解决时钟回拨
- 上线新节点时,通过RPC获得其他所有leaf服务的系统时间(
sum(time)/nodeSize),相差超过阈值,则启动失败 - 老节点在运行过程中,定时往zookeeper登记自己的时间戳,时间不对就失败(告警重试)
- 上线新节点时,通过RPC获得其他所有leaf服务的系统时间(
目前Leaf的性能在4C8G的机器上QPS能压测到近5万/s,TP999 1ms,已经能够满足大部分的业务的需求。每天提供亿数量级的调用量。



