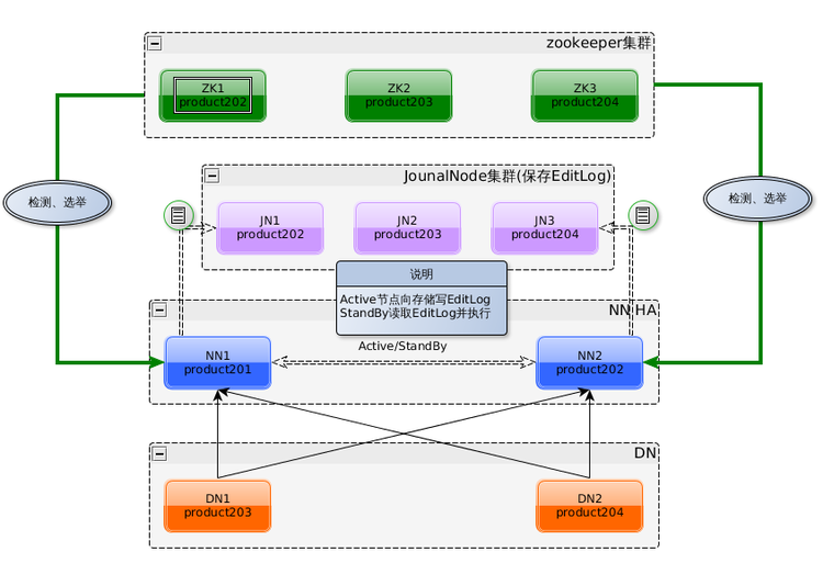
架构示例
| 主机名 | IP | 服务 | 进程 |
|---|---|---|---|
| HA1 | 192.168.140.130 | Hadoop | NN(active), ZKFC |
| HA2 | 192.168.140.131 | Hadoop | NN(standby), ZKFC |
| HA3 | 192.168.140.132 | Hadoop | RM(active) |
| HA4 | 192.168.140.133 | Hadoop | RM(standby) |
| HA5 | 192.168.140.134 | Hadoop Zookeeper |
DN, NM, JN, QPM |
| HA6 | 192.168.140.135 | Hadoop Zookeeper |
DN, NM, JN, QPM |
| HA7 | 192.168.140.136 | Hadoop Zookeeper |
DN, NM, JN, QPM |
节点含义: Hadoop-2.节点
- QPM: QuorumPeerMain Zookeeper 进程
安装软件
安装 Java, Hadoop, Zookeeper(Docker swarm)
- Linux-yum安装jdk11
- Zookeeper-高可用集群部署[DockerSwarm]
tar -zxvf hadoop-3.3.5.tar.gz -C /opt/hadoop- 配置环境变量
配置网络环境
- 同步时间
- 修改hosts文件
vi /etc/hosts:192.168.140.130 HA1192.168.140.131 HA2192.168.140.132 HA3192.168.140.133 HA4192.168.140.134 HA5192.168.140.135 HA6192.168.140.136 HA7
- 关闭防火墙
systemctl stop firewalld.servicesystemctl disable firewalld.servicefirewall-cmd --stat
- 修改主机名
vi /etc/hostname- 分别配置为
HA1,HA2,HA3,HA4,HA5,HA6,HA7
- 分别配置为
- 配置免密钥登陆(主要针对NN和RM节点)
ssh-keygen -t rsassh-copy-id HA1ssh-copy-id HA2ssh-copy-id HA3ssh-copy-id HA4ssh-copy-id HA5ssh-copy-id HA6ssh-copy-id HA7
Hadoop配置文件
/opt/hadoop/hadoop-3.3.5/etc/hadoop/:
hadoop-env.sh:export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.18.0.10-2.el9_1.x86_64core-site.xml<configuration> <!-- 指定 hdfs 的 nameservice 为 bi --> <property> <name>fs.defaultFS</name> <value>hdfs://bi/</value> </property> <!-- 指定 hadoop 临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop/tmp</value> </property> <!-- 指定 zookeeper 地址 --> <property> <name>ha.zookeeper.quorum</name> <value>HA5:2181,HA6:2181,HA7:2181</value> </property> </configuration>hdfs-site.xml<configuration> <!--指定 hdfs 的 nameservice 为 bi,需要和 core-site.xml 中的保持一致 --> <property> <name>dfs.nameservices</name> <value>bi</value> </property> <!-- bi 下面有两个 NameNode,分别是 nn1, nn2 --> <property> <name>dfs.ha.namenodes.bi</name> <value>nn1,nn2</value> </property> <!-- nn1 的 RPC 通信地址 --> <property> <name>dfs.namenode.rpc-address.bi.nn1</name> <value>HA1:9000</value> </property> <!-- nn1 的 http 通信地址 --> <property> <name>dfs.namenode.http-address.bi.nn1</name> <value>HA1:50070</value> </property> <!-- nn2 的 RPC 通信地址 --> <property> <name>dfs.namenode.rpc-address.bi.nn2</name> <value>HA2:9000</value> </property> <!-- nn2 的 http 通信地址 --> <property> <name>dfs.namenode.http-address.bi.nn2</name> <value>HA2:50070</value> </property> <!-- 指定 NameNode 的 edits 元数据在 JournalNode 上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://HA5:8485;HA6:8485;HA7:8485/bi</value> </property> <!-- 指定 JournalNode 在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/hadoop/journaldata</value> </property> <!-- 开启 NameNode 失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.bi</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 配置 sshfence 隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>mapred-site.xml<configuration> <!-- 指定 mr 框架为 yarn 方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>yarn-site.xml<configuration> <!-- 开启 RM 高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定 RM 的 cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定 RM 的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定 RM 的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>HA3</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>HA4</value> </property> <!-- 指定 zk 集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>HA5:2181,HA6:2181,HA7:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>workers(slavesin Hadoop2)- NN 节点的 workers 指的是 DN 节点
- RM (yarn)节点的 workers 指的是 NM 节点
HA5 HA6 HA7
- 使用
scp -r将配置好的目录复制到其他机器
启动
- 启动 Zookeeper 集群
- 启动 JN (HA5, HA6, HA7):
hadoop-daemon.sh start journalnode - 格式化 NN (HA1 上执行):
hdfs namenode -format- 使用
scp -r将core-site.xml文件中配置的hadoop.tmp.dir目录复制到 NN standby 节点 (HA2), 为了保持同步
- 使用
- 格式化 ZKFC (HA1 上执行):
hdfs zkfc -formatZK - 启动 HDFS (HA1 上执行):
start-dfs.sh - 启动 YARN (HA3 上执行):
start-yarn.sh - 启动 YARN standby (HA4 上执行):
yarn-daemon.sh start resourcemanager
JAVA 客户端
- 将集群配置文件中的
core-site.xml,hdfs-site.xml拷贝到项目的resources目录 FileSystem指定 hdfs 的 nameservice 为 biFileSystem fs = FileSystem.get(new URI("hdfs://bi/"), new Configuration(), "root");



![Zookeeper-高可用集群部署[DockerSwarm]](/medias/featureimages/24.jpg)